Audio, Speech, & Language Processing
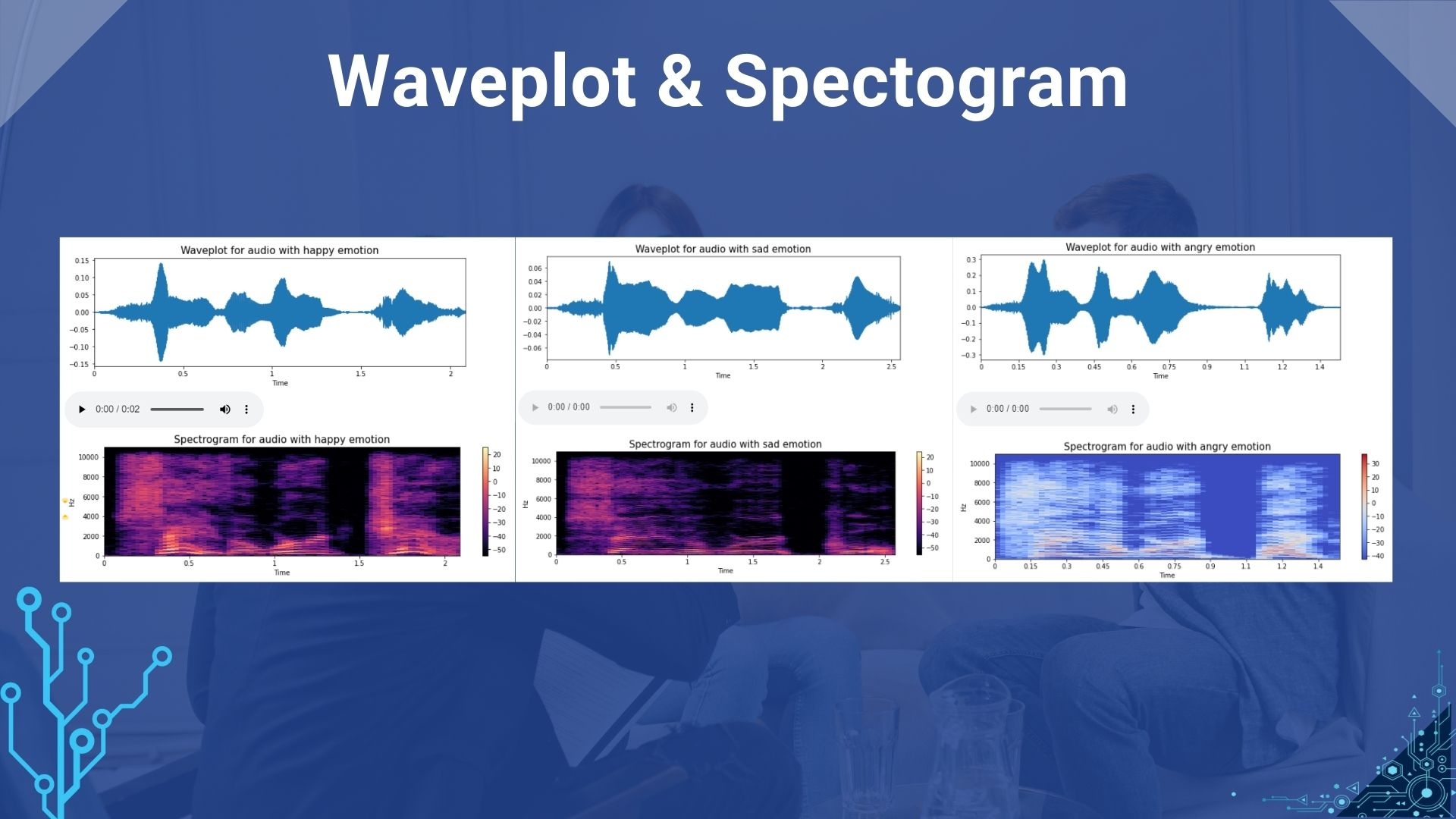
In the interaction between humans and computers, the ability to recognize, interpret, and respond to emotions expressed in speech is needed. Until now, there is very little research for speech emotion recognition (SER) based on Indonesian. This is due to the limited corpus of Indonesian data for SER. In this study, a SER system was created by taking a dataset from an Indonesian TV series. The system is designed with the ability to carry out the process of classification of emotions, namely four classes of emotional labels angry, happy, neutral and sad. For its implementation, the deep learning method is used, which in this case the CNN method is selected. In this system the input is a combination of three features, namely MFCC, fundamental frequency, and RMSE. From the experiments that have been carried out, the best results have been obtained for the Indonesian language SER system using the MFCC input + fundamental frequency, which shows an accuracy rate. This research able to provide an overview for researchers in the SER field, about how to select speech signal features as input in testing and make it easier for the steps to develop their research.